Lately there seems to be a lot of discussion around regarding the use of short keyids as a large number of duplicates/collisions were uploaded to the keyserver network as seen in the chart below:
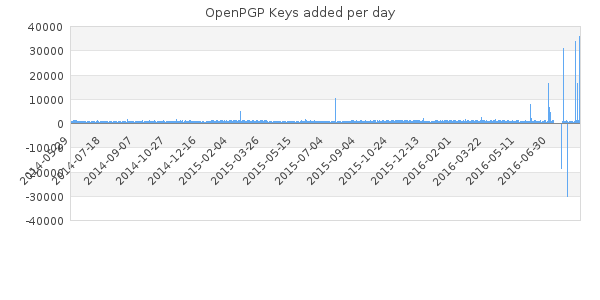
The problem with most of these posts are they are plain wrong. But lets look at it from a few different viewpoints, one of which is the timing of the articles. For OpenPGP V4 keys the short keyid are the lowest 32 bits of the fingerprint. The specific keys that were published, some 20,000 keys that duplicate the strong set keys, were generated by evil32 in 2014, so nothing is actually new here (except it being published on the keyservers), and adding to that the triviality of short keyid collisions has been known from the start, which is ok, since it is just a short, convenient identifier.
What was interesting with the evil32 keyring however was demonstrating doing this on a large scale, by cloning the full strong set of the common Web of Trust (WoT). A strong set can be described as "the largest set of keys such that for any two keys in the set, there is a path from one to the other".
So what have we learned so far - when discussing keys there is such a thing as a path between keys existing in a strong set (that requires the path to be complete in both directions), the path we're talking about is a signature path, whereby Alice and Bob meet up at a conference and exchange data and check IDs after which they sign each others keys, then a path exists.
So where does duplicate short keyids make things diffused from a security perspective? Absolutely nowhere! The issue arise when people start using OpenPGP without understanding any concept of operational security or key management, and start using encryption and digital signatures "because it is cool" without actually verifying any of the recipients' keys. They go looking for a key on the keyservers, gets two results and are confused, making a large fuss about it.
In many ways we should be thankful that the duplicate keys are on the keyservers and starts confusing people, maybe they will start doing some key verification now? Not likely, when even Computer Emergency Response Teams (CERT) such as the dutch don't understand basic concepts of security and starts wanting to prove the negative and detecting duplicate keyids. In an intentional attack, all the keys found might very likely be an attacker, you should verify positively with the person you want to communicate with, or through your network of trusted peers (that you assign a trust level to when calculating the WoT), never, ever, try to guess what is wrong by proving something is false.
The most common suggestion over the past few days seems to evolve around "Use the long keyid", whereby the short keyid is a 32 bit identifier, the long keyid increases the size to 64 bits, and for GnuPG this can be achieved using "keyid-format 0xlong" in gpg.conf. And sadly, the suggestion is based on the same misconception. For one thing, generating colliding 64 bit keyids is also possible, but the really scary thing is it still assumes users are not properly verifying the keys they are using with the full fingerprint in place, normally along with the algorithm type and creation date, for which purpose I carry around the following slip of paper:

The moral? If you actually do your job and validate the keys of your correspondents either directly or through trusted peers (including Certificate Authorities) that have signed the key, whether you're using the short keyid or the long keyid as reference is mostly without importance as the selection of keys you look at are already verified, and the likelihood of having collission on that set of keys is slim.
The one thing that is very sure is that the existence of duplicate/colliding short keyids on the keyserver networks does not impact security if OpenPGP is used properly (if anything it improves it if people start using their brain)
